Hi! My name is Michael and I’m a developer advocate and cloud native ambassador. Here, I share some thoughts and considerations around using cloud native technologies, including Kubernetes, observability tools such as Prometheus, service meshes, and serverless offerings.
- Why?
- Release early, release often
- Containers
- Kubernetes
- Observability
- Service meshes
- Serverless
- Security
- Developing
Why?
Why you would want to read this
You have heard about cloud native technologies and success stories. You wonder where and how to start and get the most out of it. Congrats! You’re exactly right here.
Why I am writing this
A fair part of my work consists of being on the road, talking with folks at events, with customers on-site, meeting up with partners to understand their offerings, helping on StackOverflow and on various Slack channels. I learn something every time when I’m having these discussions and even more when someone asks me how to do something or why things are like they are. This is my attempt to share some of this knowledge, to give back to the community. Also, I wanted to have a place on the Internetz I can point people to. Talking about human scalability, ha!
Let’s talk about release early, release often
Before we even get to the meat, let’s first make sure we’re on the same page concerning what the unit of delivery is. If you come from a background where a team of people has been working on a big monolithic app with a gazillion of features, you may be used to, say, one or two releases per year. Each of the releases is a huge effort, involving many tools and people, including many features and fixing many bugs. So, in this context it’s more than understandable that you don’t, no, you can’t release more often. It’s just too expensive, both time-wise and money-wise.
The first time you hear people reporting that they’re releasing a new version of their app many times every day or maybe even a couple of times per hour you might go like: woah, that’s some crazy talking there. But bear with me for a moment. Don’t compare that kind of releases with your monolith-once-per-year release. They are fundamentally different in a number of ways:
- Rather than shipping, say, 60 new features and bug fixes per release, it’s one (or maybe two?) features per release we’re talking about in this context.
- Each release only incrementally changes the app, some of the new features might only be seen by a small subset of the user base.
- Also, each feature might be as tiny as: change the input field validation or add one more option to this dialog over there; chances are they’re so small you might not even notice them unless you’re a heavy user of the app.
- Even if the, say, one new feature of the current release number 42 of today is broken, not much harm is done since the next release is only a few hours away and with that you get the chance to either fix it or roll it back.
- Last but not least—especially true for native Web apps—every time you reload the page you may end up using a new version of the app. The app may consist of many (hundreds of?) microservices.
This idea of ‘small batches’ was, to my knowledge, first popularized by the 2013 book The Phoenix Project, although the idea existed already for quite some time. For example, I remember reading Michael Nygard’s Release It! from 2007 where he essentially argued the same principles. I’m pretty certain that in a number of forward-looking organizations and communities, the small batches paradigm, that is, releasing early (to get direct end-user feedback) and release often (to establish fast feedback cycles) has been practiced for more than 20 years. I suppose the point I’m trying to make: at time of writing, in 2018, we’re now in a good place where we can resort to a wealth of good practices from practitioners across different verticals and domains.
Some of the good practices (such as zero-downtime deployments or A/B testing) and abstractions (for example, load-balancers or the retry and timeout pattern) that so far existed mainly in more informal shapes, including tribal knowledge, blog posts and books have now been, quite literally, encoded in software. You might have guessed it already, this piece of software I’m talking about here, that takes the lessons learned of running containerized microservices (at scale) and provides it to you in a free and open source format is, indeed, Kubernetes.
Let’s talk about containers
So containers are really just Linux process groups on steroids. Using Linux kernel features such as namespaces, cgroups, and copy-on-write filesystems, containers allow you to manage application-level dependencies, such as runtimes or libraries:
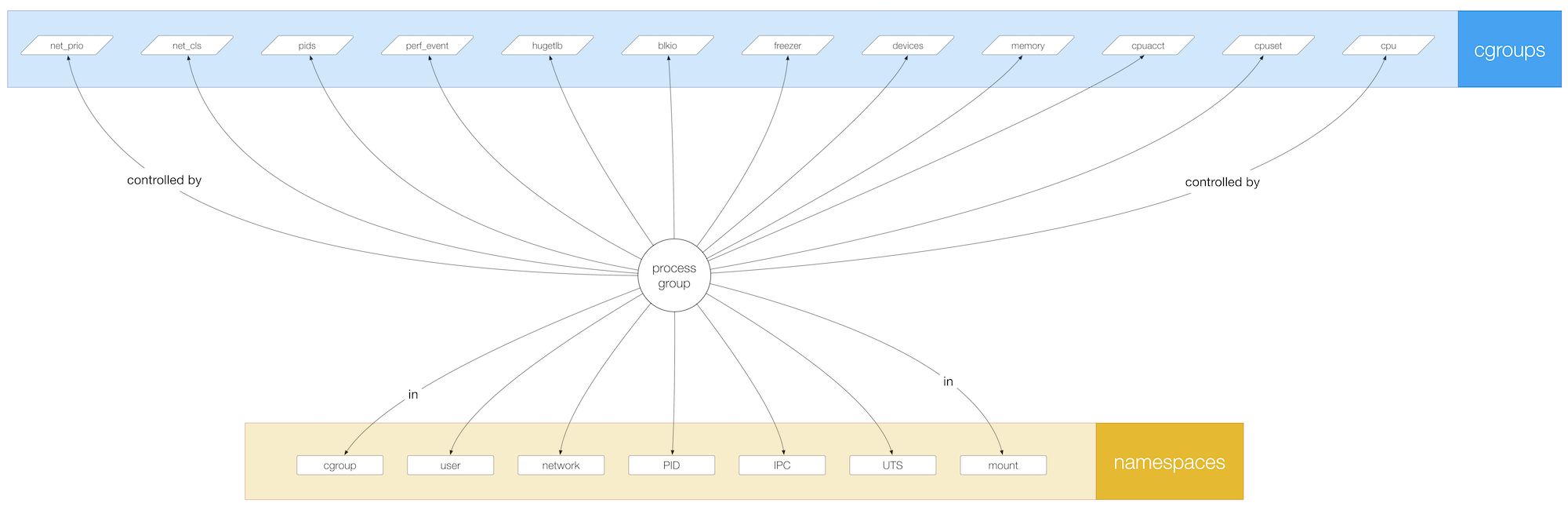
In contrast to virtual machines (VM), all containers on a machine share the same Linux kernel. Under the Open Container Initiative (OCI), both the container runtime aspects as well as the container image format has been de-fact standardized.
For cases where the learning curve and operational overhead of a full-blown container orchestrator such as Kubernetes can not be justified, you can run single containers supervised by systemd or, if you run in the public cloud, leverage offerings such as AWS Fargate or Azure Container Instances.
Let’s talk about Kubernetes
You want to benefit from Kubernetes, right? You want portable applications, getting features out to your customers faster, use modern deployment mechanisms, have autoscaling, and more?
I’ve got good news and not so good news for you. Yes, it’s totally feasible, but you gotta do your homework first. You have to first do the, surprise, boring stuff (!)
Let me walk you through it …
Before we jump into the how, let’s have a high-level view on a cloud native stack based on Kubernetes, which might look something like the following:
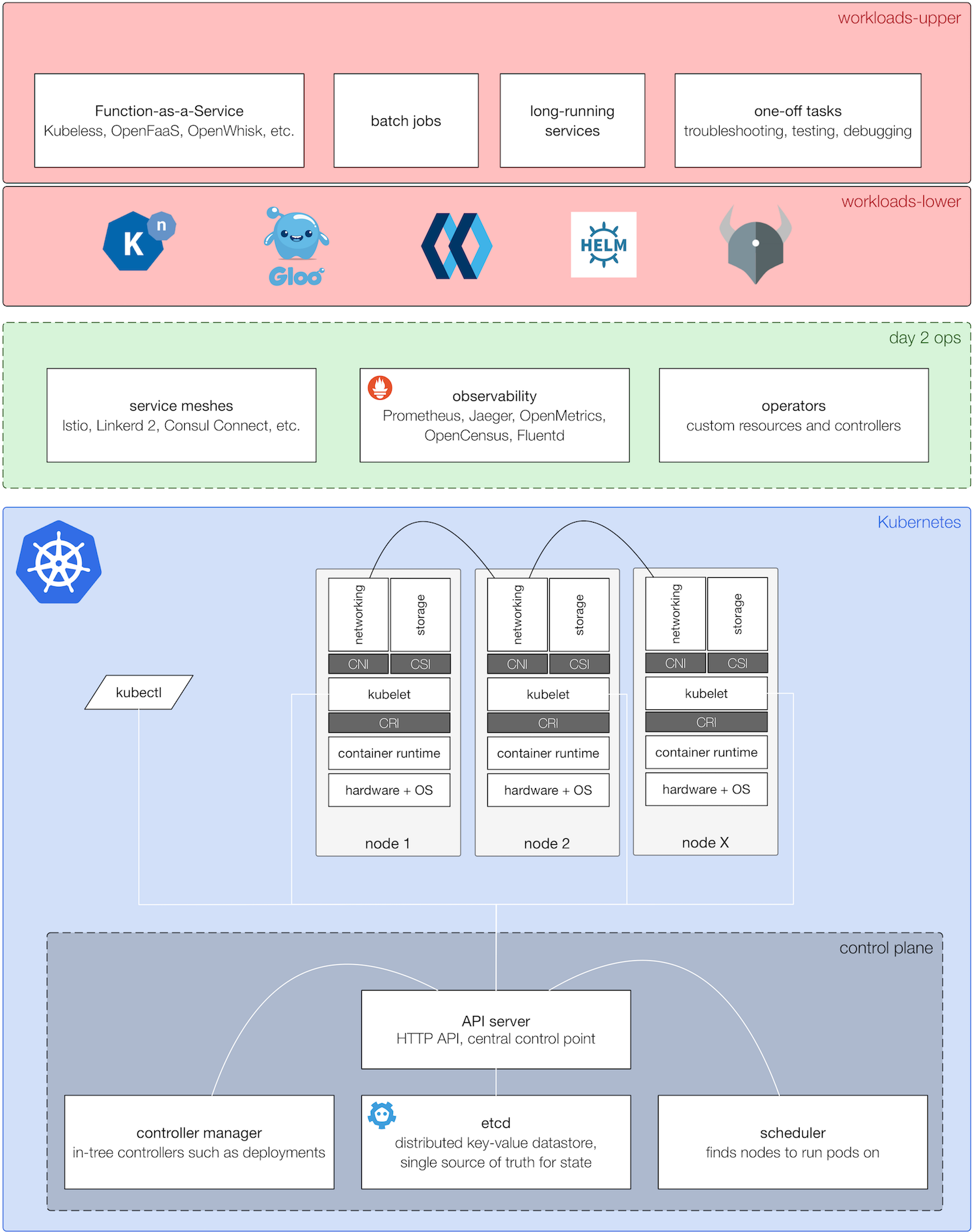
The basis of the Kubernetes-based cloud native stack is unsurprisingly Kubernetes. On top of that you’ll find a collection of tools and components collectively labelled as “day 2 operations”, from service meshes (for intra-cluster service-level traffic management and insights) to operators, managing the application life cycle (install, upgrades, maintenance, etc.). I’ve split the workloads into two parts: lower-level (abstractions or building blocks) such as Knative, registries such as Quay.io, or OPA. The workloads you actually care about, the ones you interact with directly, such as a long running service exposing a HTTP or gRPC interface or an event-driven function invocation via FaaS, are in the upper level.
Begin at the beginning
“Begin at the beginning,” the King said, very gravely, “and go on till you come to the end: then stop.”
—— Lewis Carroll, Alice in Wonderland
So, what is the beginning? It starts with your team and your wider organization. Like, everyone. This is the hard part and unfortunately the technologies available can’t help you there. Make sure that developers and folks with ops roles are incentivized in the same direction. Go for lunch together. Talk. Whatever it takes, make sure you’re on the same page for what is coming. Do it now, I’ll wait here …
OK. You ready?
Let’s get to the “easy” stuff, the tech. Here’s a little checklist, in this order:
- All of our source code is in a version control system such as Git, Mercurial, svn or whatnot.
- We know about container (base) image hygiene such as footprint, build vs runtime environment, attack surface, etc.
- We have a CI/CD pipeline and know how to use it.
- We have a (private, secure) container registry and know how to use it.
- Our developers have either local Kubernetes environments or access to dedicated namespaces for day-to-day development.
- Our dev and ops folks have a 360 view on apps and infra, we use observability tooling everywhere.
Checked all items off the list? Pinky promise?
Cool, you’re ready …
So, what’s next? Well, think about what kind of app you’re doing. Is it a lift and shift of an existing app? Breaking down a monolith into a bunch of microservices? Are you writing a native app from scratch? Here are some rough guidelines and indicators for each case:
- You have a commercially available off-the-shelf (COTS) app such as WordPress, Rocket Chat or whatever and you want to run it on Kubernetes. The app itself is not “aware” it runs on Kubernetes and usually doesn’t have to be. Kubernetes controls the app’s life cycle, that is, find node to run, pull the container image, launch container(s), carry out health checks, mount volumes, etc, and that is that. You benefit from Kubernetes as a runtime environment and that’s fine.
- You write a bespoke app, something from scratch (with or without having had Kubernetes as the runtime environment in mind) or an existing monolith you carve up into microservice. You want to run it on Kubernetes. It’s roughly the same modus operandi as in the case of the COTS app above, but with a twist:
- Now that you have a bunch of microservices, you can ship features faster. If and only if your organization allows it. Roll out a new service and you’re done. Do A/B or canary testing, leverage fine-grained security via RBAC.
- Oh my, you have some microservices and not a single monolith now … how do you know where to look at when things are slow and/or break? See the tracing section for some answers.
- The case of a cloud native or Kubernetes native application. That is, a an application that is “fully aware” it is running on Kubernetes and is designed to access the Kubernetes APIs and resources, at least to some extent. You don’t have to go all the way to use things like the Operator Framework, although that’s also a nice goal, but you typically would leverage Kubernetes custom resources and/or write a controller that queries or manipulate Kubernetes proper resources such as pods or services.
Kubernetes good practices
So, let’s face it, there are no best practices, but over time the community documents and collects things that can maybe be called “good practice”. As in: worked for me, in my setting but YMMV.
Turns out it pays off to study the Kubernetes architecture first in-depth to get a good idea of the APIs and the interaction of the components as well as the standardized interfaces for networking (CNI), container runtime (OCI and CRI), and storage (CSI):
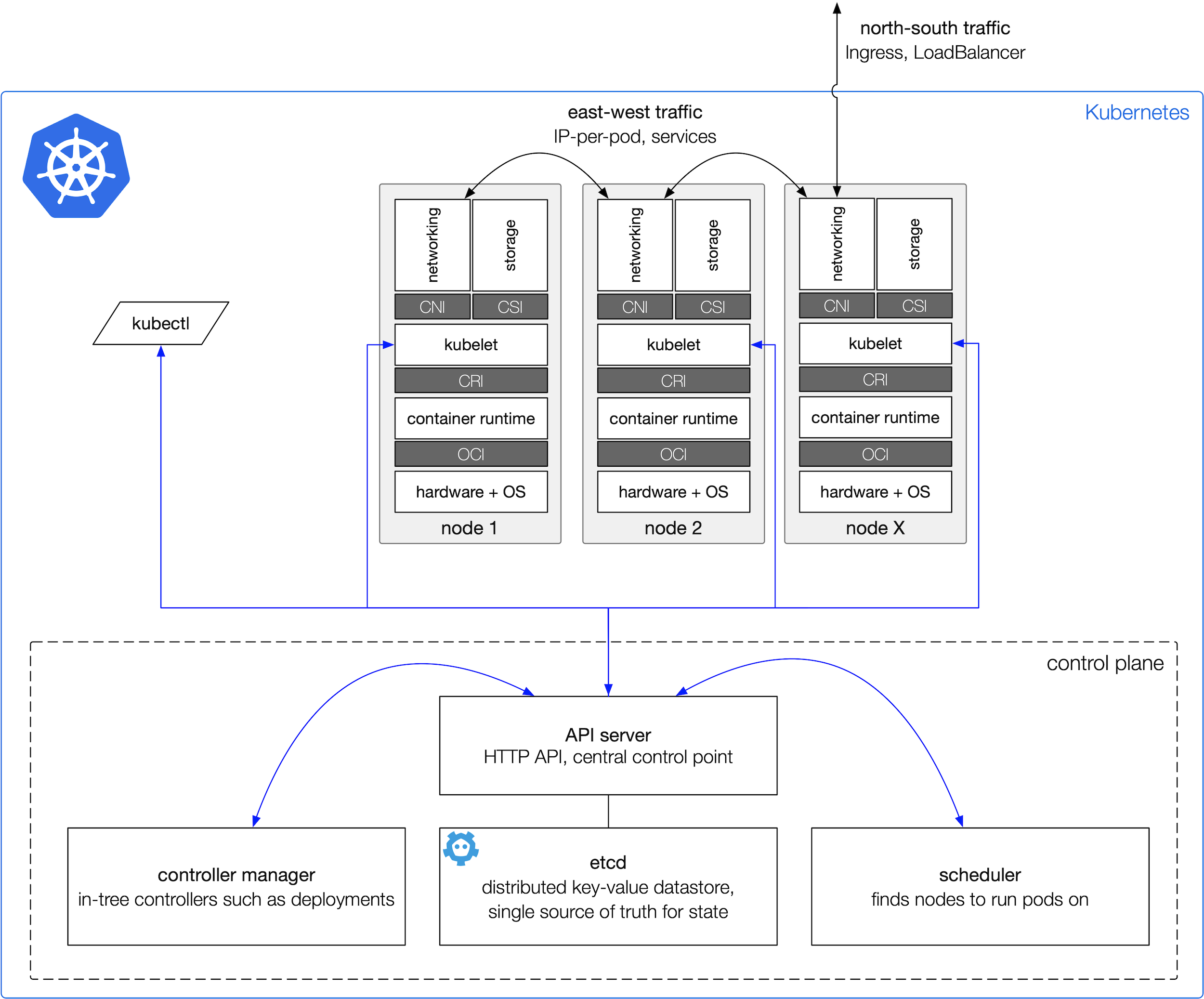
Here are some more pointers to good practices and/or collections of such, to get you started:
- Overview and intro:
- Install and day 2 ops:
- Functional areas:
Let’s talk about observability
So observability, sometimes also called o11y, because: why not? :)
I’ll keep it simple and talk for now about the cloud native monitoring standard Prometheus and then continue with tracing.
Prometheus
It’s simple. Install it and use it together with Grafana. Also, if you’re looking for retaining your metrics in the long term, there are options (@@TODO: update dat link when blog post goes live).
The PromQL query language is super powerful and actually not that hard to learn, here you see it in action (kudos to Robust Perception):
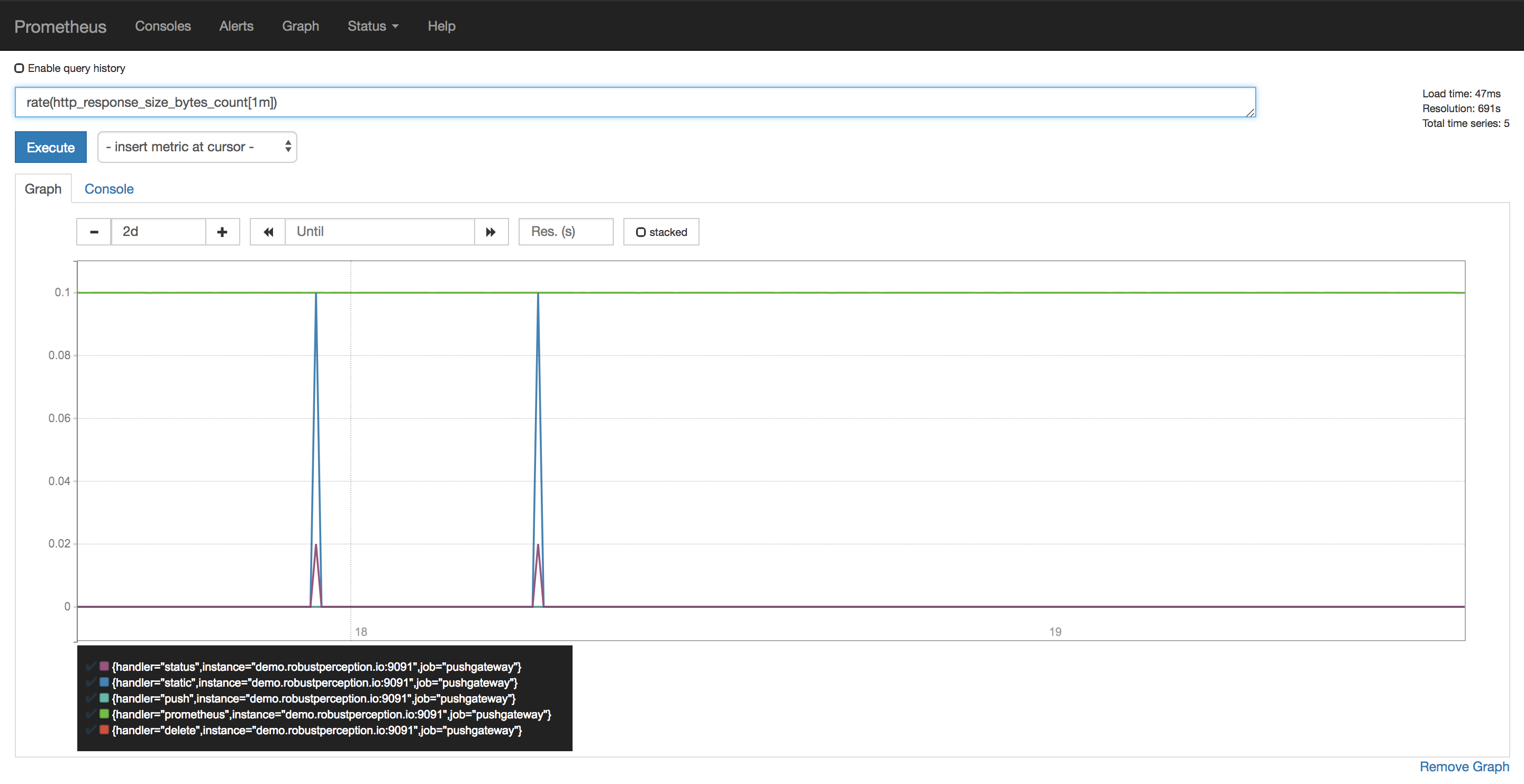
Ah, one more thing in this context: keep an eye on the OpenMetrics project. It’s a relatively new CNCF project that has its roots in Prometheus and will enable interop in this space.
Some pointers to good practices and/or collections of such, to get you started:
- Read the Prometheus: Up & Running book by Brian Brazil
- Read the Monitoring with Prometheus book by James Turnbull
- Evolution of Monitoring and Prometheus
- 4 open source monitoring tools
- Try out PromQL in Robust Perception’s Prometheus demo installation
- Watch videos from PromCon:
Tracing
You have a bunch of (containerized?) microservices that make up your app. Let’s say that on any given request path you have a couple—maybe only 5 but maybe 20 or more—microservices involved in processing the request. How can you not only figure out which one of the many microservices on the request path is broken (relatively straight forward) but which one is slow or busy?
Here, distributed tracing can help developer or appops and while some experts advocate for being conservative rolling out tracing, I can’t imagine how one would successfully do microservices without tracing or something equivalent. It’s like flying blind in a plane you’ve so far only known from the passenger cabin and you notice a warning saying that you’re about to crash … and not even knowing where to look for the potential problem. Doesn’t sound like a great place to be in.
Rather than trying to time-sync log entries across different nodes—good luck unless you can do TrueTime—the idea of (distributed) tracing is to assign each incoming request a unique ID (UID). This UID is passed through by each microservice touching the request, for example, using HTTP headers. The tracing tool then can stitch together the traces by looking at each invocation and knowing which microservice did what. The result is something like this (produced using the Jaeger tracing tool):
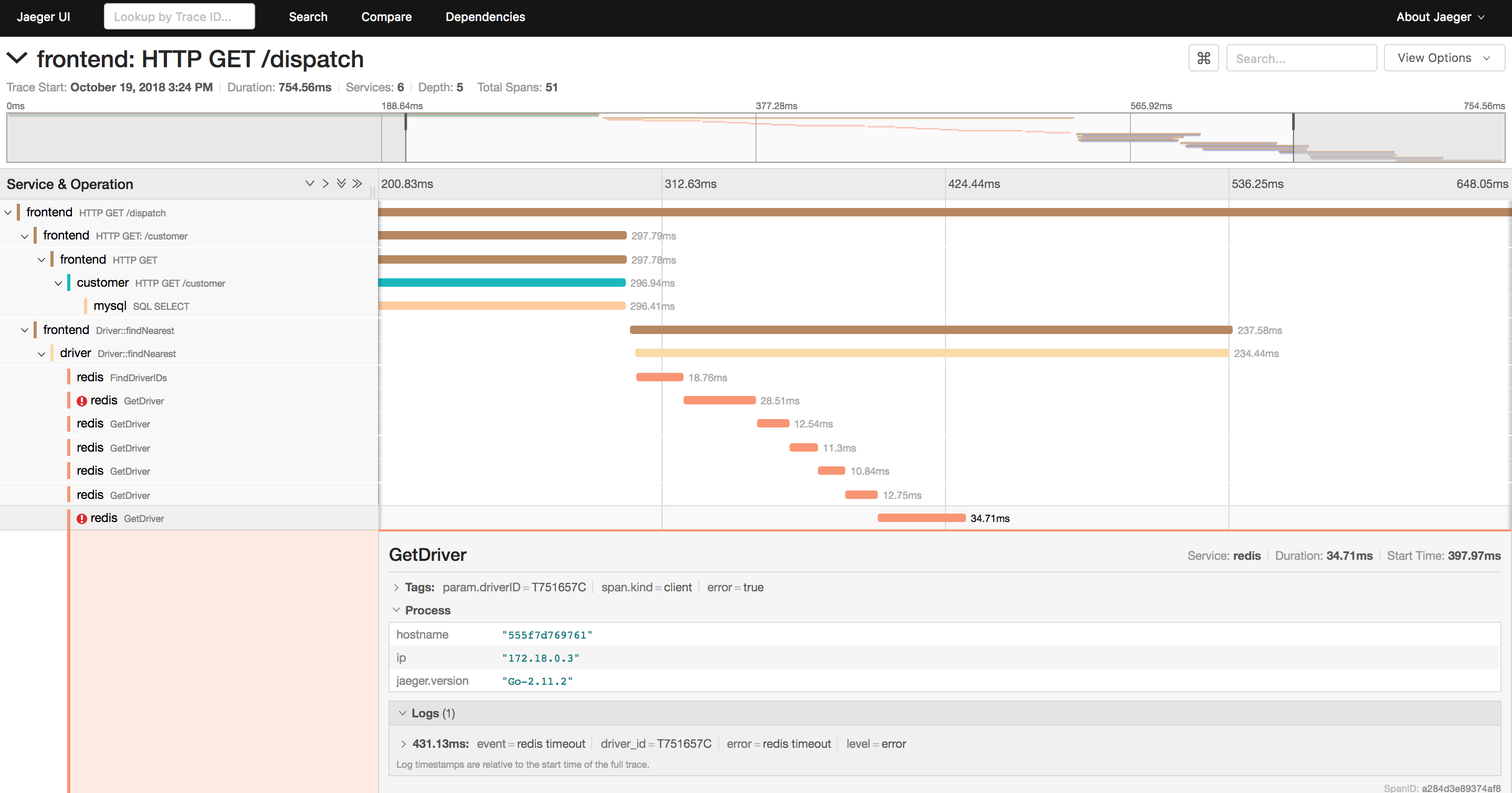
As it is sometimes the case in cloud native land (erm, container engines) we have not one but two CNCF projects here at our disposal, with overlapping goals but different approaches:
- OpenCensus, which explains itself with being ‘a vendor-agnostic single distribution of libraries to provide metrics collection and tracing for your services’. Tooling (in alphabetical order): Exporters for Go, Java, Node.js, and Python, Go kit, Google Stackdriver, MongoDB, Redis clients, and others.
- OpenTracing, which announces itself with the headline to offer ‘vendor-neutral APIs and instrumentation for distributed tracing’. Tooling (in alphabetical order): Datadog, Instana, LightStep, Jaeger, Zipkin and others.
I’m not going to make a recommendation here, it’s a loaded discussion, so pick which one you like or flip a coin.
Some pointers to good practices and/or collections of such, to get you started:
- The life of a span
- 3 open source distributed tracing tools
- Distributed Tracing with Jaeger & Prometheus on Kubernetes
- Use OpenTracing with Golang and Hot R.O.D. demo Katacoda scenario
- Debugging Microservices: How Google SREs Resolve Outages
- Debugging Microservices: Lessons from Google, Facebook, Lyft
Let’s talk about service meshes
“There is nothing quite so useless, as doing with great efficiency, something that should not be done at all.”
A word on maturity: we’re, at time of writing this in end of 2018, with service meshes where we were between 2015 and 2017 with container orchestrators. Remember the “container orchestration wars”? We had Swarm, Mesos/Marathon and then Kubernetes came along (honorable mention: Nomad, which I very much like, just a little late to the party). It became apparent for folks that it’s prolly a good idea to use a container orchestrator but it was unclear which one to pick since there was no clear winner. So folks often ended up doing home-grown combos of bash scripts and using Puppet, Chef, or Ansible to orchestrate containers. Well, with end of 2017, Kubernetes established itself as the industry standard in this realm and the discussions are nowadays kinda moot.
Again, we’re early days concerning service meshes. But, if you have a non-trivial number of microservices (10? 20? 30?) and you find yourself rolling your own solution to manage observability, shape traffic, intra-service or intra-cluster mutual TLS, etc. then maybe, just maybe you’re in the right place to consider a service mesh. Here are some options:
- Istio: the 500 pound gorilla with lots of industry buy-in (IBM, Google, Red Hat). Uses Envoy as the data plane and offers a range of features, from traffic control to observability to failure injection to mTLS. Also, make sure to evaluate it carefully.
- Linkerd2: a nice and lightweight alternative to Istio with a focus on developers. I took a closer look at it here.
- Consul Connect: can’t say much since I haven’t tried it but looks promising to me.
- AWS App Mesh: an Amazon-specific mesh using Envoy as its data plane and comes with a fully managed control plane, can be used with Fargate, ECS, EKS, and also self-managed Kubernetes on EC2.
- SuperGloo: meta-mesh to run multiple service meshes (Istio, Linkerd2, Consul Connect, AWS App Mesh).
Here I show you Linkerd2 in action:
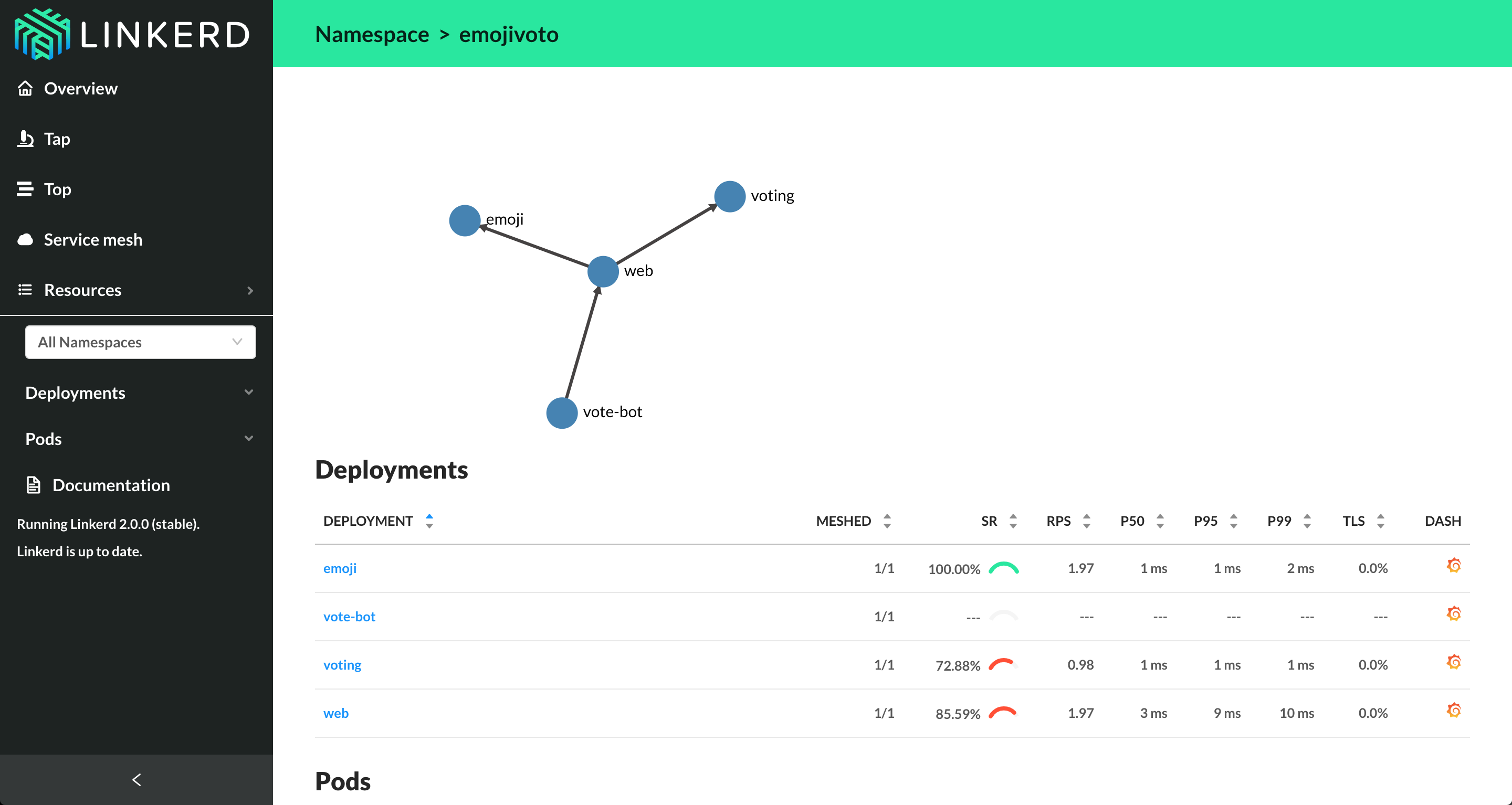
Service mesh good practices
Some pointers to good practices and/or collections of such, to get you started:
- The Service Mesh: Past, Present, and Future
- The Enterprise Path to Service Mesh Architectures
- The Service Mesh
- Introducing Istio Service Mesh for Microservices
- Istio in Action
Let’s talk about serverless
So, yeah, serverless is the ‘new’ kewl kid in town. Let’s get something out of the way, up-front: it’s kinda not really useful to position serverless and containers against each other since that’s comparing apples and oranges, but nevertheless that’s often the case happening, nowadays. So, let us not go there and focus on what serverless is and what you can do with it:
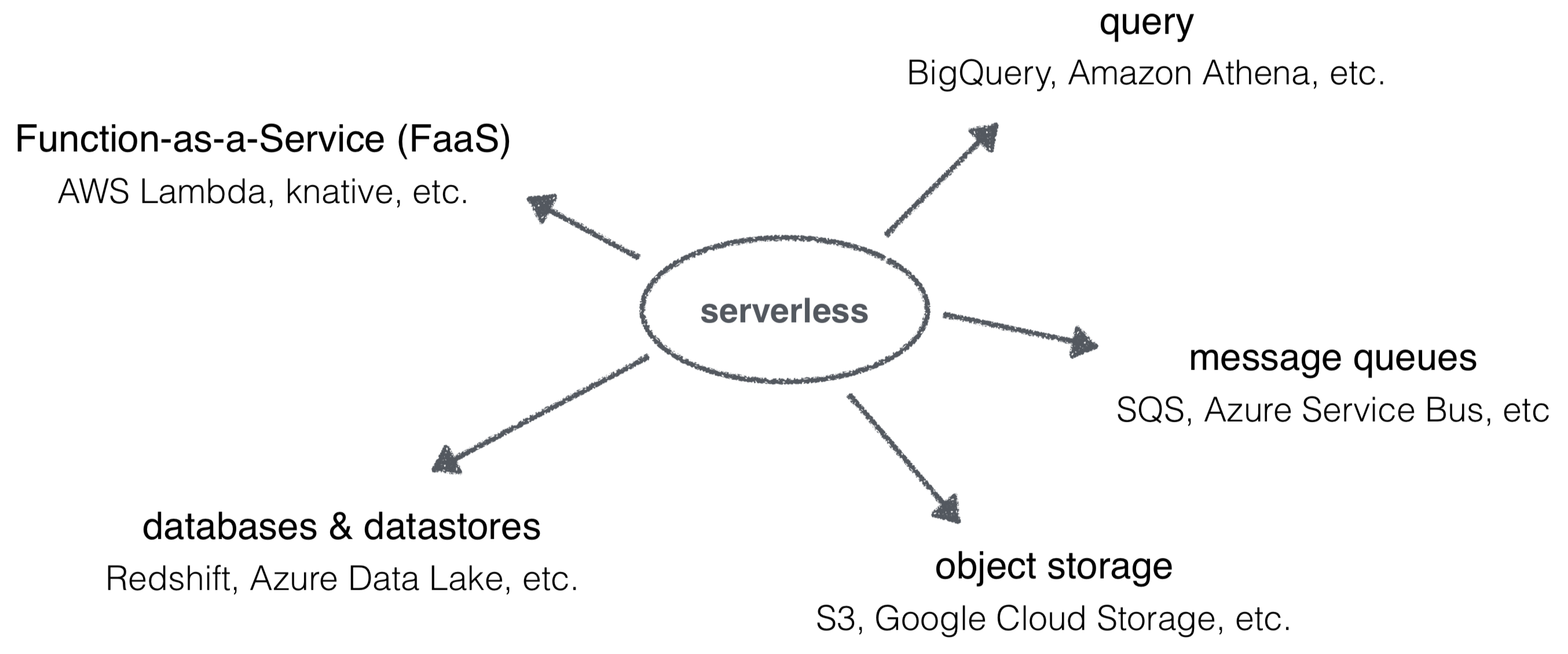
Serverless is an umbrella term for a class of technologies, focusing on the execution (no provisioning, managed, and native auto-scaling) and typically with a ‘pay only for what you actually use’ billing model, rather than on a fixed basis, such as on a monthly basis.
One of the most popular serverless offerings is the so called Function-as-a-Service (FaaS) with its three components triggers, the function management part, and the integrations with stateful systems:
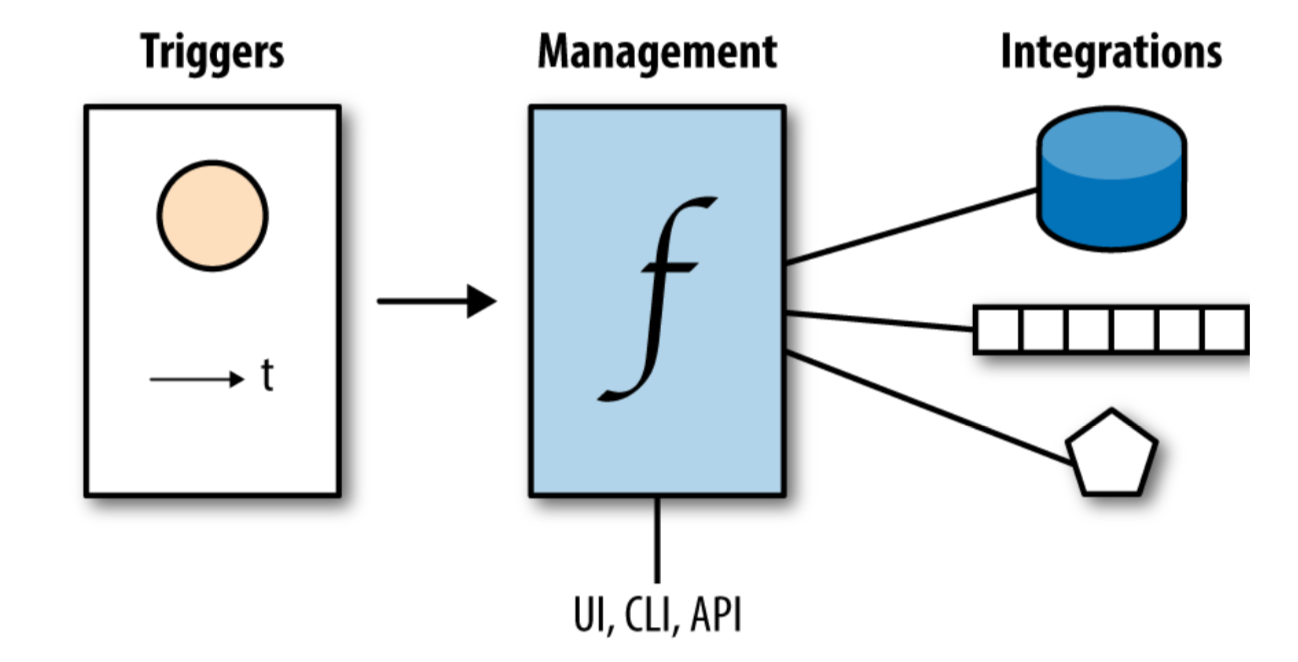
Triggers such as an HTTP API call, time, or an upload to an S3 bucket cause function invocations. The function management part allows you to update and configure functions, typically via CLI and/or UI, based on a HTTP API, and the integrations allow the functions to externalize state.
With AWS Lambda, Amazon has been trailblazing this area since 2014 and it is nowadays used in a range of event-driven use cases.
Whenever someone says serverless, erm, FaaS then I usually ask: Where?
In the public cloud such as AWS Lambda or Azure Functions or on top of Kubernetes? Also, one should not underestimate the fact that there are certain challenges that come along with it; though, in all fairness, some do overlap with containers.
I’ve been active in serverless land for a couple of years now and recently asked myself how does the same app look as a monolith, as a containerized microservice app, and using FaaS.
The last year or so brought a lot of changes: the CNCF Serverless Working Group has been super active, for example around CloudEvents, and then of course Google took everyone by surprise in launching knative—check out the serving and eventing bits especially. I get the feeling currently many (open source) projects are re-platforming on knative—in the context of OpenWhisk I can say this for sure to be the case—and it will be interesting to see if there will ever be a real alternative to the serverless framework.
Serverless good practices
Some pointers to good practices and/or collections of such, to get you started:
- O’Reilly has a great collection of resources here with Learn about serverless with these books, videos, and tutorials
- Read from and listen to Mr Paul Johnston
- Attend one of the dozens Serverless conferences around the world
Let’s talk about security
Oh boy. So, I’m currently reading Bruce Schneier: “Click Here to Kill Everybody” and while it’s not that bad in cloud native land, I think, we certainly still have a lot of work in front of us.
In the context of Kubernetes, Liz Rice and I have collected and documented relevant security resources at kubernetes-security.info and there’s also a short book for your to download.
For serverless/FaaS, I’d suggest you check out Yan Cui’s excellent post Many-faced threats to Serverless security and maybe have a look at this very informative Black Hack 2017 talk on Hacking Serverless Runtimes: Profiling AWS Lambda Azure Functions & More with a slide deck here.
Let’s talk about developing
From a developer perspective, cloud native could involve a range of things depending on what environment you’re in: from Kubernetes (container-based) environments to serverless (FaaS) environments.
Developing on Kubernetes
In the case of developing an app that’s supposed to run on Kubernetes on needs to create a container image with the app in it (for example, as a jar file, binary, script) that must be placed into a container registry for Kubernetes to launch the application container.
So one end-to-end iteration, from code change to running the app consists of the following phases:
- You first need to build a container image (locally or remote, e.g., via CI/CD pipeline), and
- then need to push the container image into a container registry.
- Via the CRI standard, the
kubeletinstructs the container runtime to pull the container image from the registry, and - then launches a new pod with the updated container image.
How to short-cut this full cycle? The approaches can roughly be categorized as follows:
- local builds, for example, using the container engine in Minikube
- sync-based by replacing binary in running container such as ksync or DevSpace
- proxy-based such as Telepresence
Interesting cloud native online prototyping, testing, and development environments:
Interesting online shell environments:
Debugger and troubleshooting tools:
Developing on Kubernetes good practices
There are a number of things you can do in the design phase, on an architectural level:
- Know the Kubernetes primitives (aka core resources such as pods, services, deployments, etc.) and know how to use them and when not to use them and define custom resources.
- Avoid strong coupling and hard-coded (start-up) dependencies, rather, implement retries and timeouts when communicating. Bonus points: out-source these communication patterns to a service mesh.
- Network bound services should listen on
0.0.0.0(that is, any local address) and not127.0.0.1(that is NOT the loopback address).
Then once you started coding:
- Apply chaos engineering.
- Make sure devs and ops have a 20/20 vision.
- Automate all the things (CI/CD, scanning, deployments, perf tests, A/B tests, etc.).
Further pointers to good practices and/or collections of such, to get you started:
- Developing on Kubernetes
- Apps life cycle
- Troubleshooting apps
- Development and Debugging with Kubernetes
- Debug a Go Application in Kubernetes from IDE
- Troubleshooting Java applications on OpenShift
© Michael Hausenblas, Jan 2019